Large language models continue to rapidly transform how we interact with software, and among the most practically impactful LLM-driven tools are AI coding assistants, which have seen explosive adoption as software engineers tap into their potential to dramatically accelerate development workflows.
Building a Benchmarking Framework with a Difference Loomery is developing a framework that assesses real-world AI coding assistant model performance through a product engineering lens.SWE-bench and LiveBench provide valuable technical insights, generally either evaluating performance on tasks that tend to be more academic in nature, or relying heavily on automation to judge the results of more realistic task outputs. We find that these benchmarks can be difficult to translate into a clear human understanding of how a model behaves in a product-focused engineering scenario representative of those we commonly encounter in our day-to-day work. ARC-AGI , assesses each leading model in terms of “a system that can efficiently acquire new skills outside of its training data” - a significant metric to evaluate, but it’s hard to determine how that impacts the application of AI coding tools in a typical software development project context.
Our Methodology Our benchmarking methodology is designed to guide our engineering best practices in terms of how we expertly harness coding assistants to maximise the product value we deliver to our clients. The challenges and repos that we assess coding assistants on are carefully selected to map directly to our day-to-day ways of working on product engineering deliverables.
Beyond the underlying models, each tool comes with ways for making the outputs more deterministic such as adding an AGENTS.md file for project context or adding SKILLS.md files specialising in specific domain areas in the case of Claude. To make our testing realistic to how we would use these tools on projects we leveraged these techniques as much as the tools allowed us rather than just relying on the raw model performance.
Insights from our First Run Pairing & Basic Prompt Format Come Out on Top Applying the 'pairing' approach (incremental use of targeted, small & frequent code-specific prompts) and/or the use of 'basic' (shorter and more concise) prompts results in higher quality output than applying their respective alternatives.
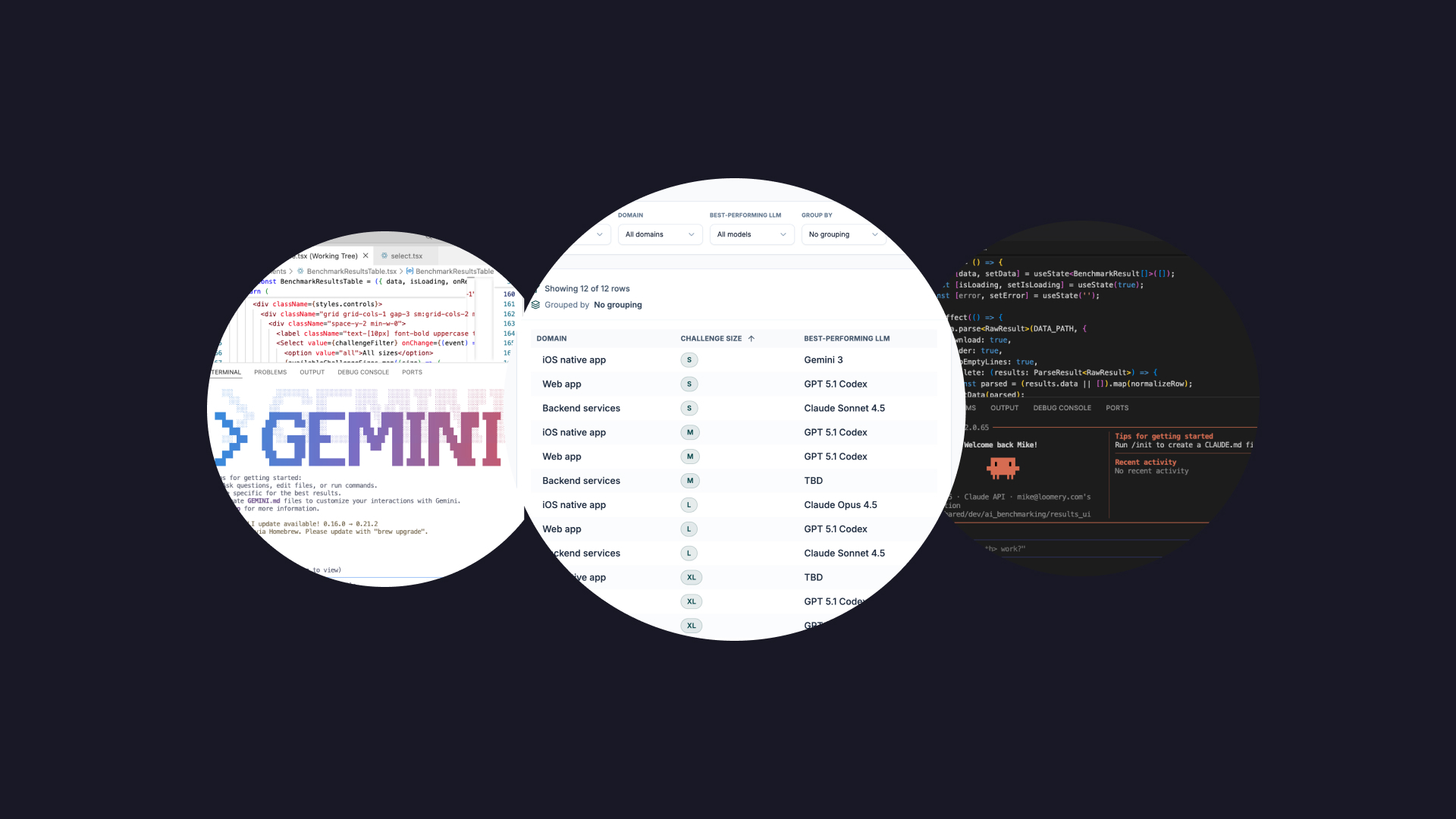
Domain-specific Findings GPT Codex performs best in the web app domain - scoring highest on challenges of all sizes In the iOS native domain, each of the leading models has its place, with Gemini performing best for small challenges, GPT Codex winning for medium-sized, and Claude Code giving the top results on large-sized challenges Claude Code generally did best on backend domain challenges, beating the opponents on all but XL-size, where GPT Codex took the crown Explore the detailed results in full here , including all the info on challenges, repos and evaluation criteria.
Building on the Foundations - Future Enhancements Exploring Prompt Engineer Personas Whilst our first run has measured performance through the lens of experienced engineers working in the engineering domains & tech stacks that they specialise in, one of our broader aims is to carry out benchmarking from the perspective of various personas, in order to inform our views on the effective use of coding assistants by specialised and non-specialised prompt engineers alike.
A - Engineering domain expert: An engineering domain expert, with a clear idea of what they want out of the model - like best practices, patterns and frameworks. Strong idea of what GREAT looks likeB - Polyglot engineer: A software engineer, but not an engineering domain expert (e.g. an Android developer coding for the backend with Python). Strong idea of general software best practices but little to no idea for domain-specific requirements and patterns. Solid idea of what GOOD looks likeC - Vibe coder: A non-engineer/non-coder, who knows what they want in terms of product features but nothing when it comes to code and engineering practice. No barometer for engineering standardsA Living Framework This is v1 of our framework and results - we are seeking your feedback and collaboration as we further develop our methodology.
What Next? Our findings can help us make more informed and intentional decisions about the ways in which we use coding assistants and the specific tools we select for given tasks.
Sign up for updates about Loomery's latest AI Coding Assistant Benchmarking Results



%201.jpg)







